Photoshopping, fraud and circular logic in research

By Mike Hearn | Daily Sceptic | July 22, 2021
It is simply no longer possible to believe much of the clinical research that is published, or to rely on the judgement of trusted physicians or authoritative medical guidelines. I take no pleasure in this conclusion, which I reached slowly and reluctantly over my two decades as an editor of the New England Journal of Medicine.
Check out this image from a peer reviewed research paper that supposedly shows skin lesions being treated by a laser:

Left: before treatment for keratoses. Right: after they were airbrushed out. (image diff is available here)
On being challenged the authors said:
The photograph was taken in the same room with a similar environment; unfortunately the patient wore the same shirt.
The journal found this explanation acceptable and forwarded the response to the complainants.
It’s becoming clear that science has major difficulties with not only a flood of incorrect and intellectually fraudulent claims, but also literally faked, entirely made up papers with random data, imaginary experiments and photoshopped images in them. Some of these papers are sold by organised gangs to Chinese doctors who need them to get promoted. But others come from really sketchy outfits like (sigh) the National Health Service, to whom we owe the masterpiece seen above.
The British Government hasn’t noticed that its doctors are massaging medical evidence. Instead this example comes from Elizabeth Bik, who runs a blog where she and a few other volunteers try to spot clusters of fraudulent papers. She embarrassed the journal in public here, and the paper was finally retracted. But she’s just a volunteer who raises money on Patreon for her work. Here’s her assessment of what’s going on:
Science has a huge problem: 100s (1000s?) of science papers with obvious photoshops that have been reported, but that are all swept under the proverbial rug, with no action or only an author-friendly correction… There are dozens of examples where journals rather accept a clean (better photoshopped?) figure redo than asking the authors for a thorough explanation.
As the only people trying to spot these fake papers are bloggers, we can safely assume that far larger numbers of papers are fake than the “thousands” they have already found and reported. For example,
0.04% of papers are retracted. At least 1.9% of papers have duplicate images “suggestive of deliberate manipulation”. About 2.5% of scientists admit to fraud, and they estimate that 10% of other scientists have committed fraud.
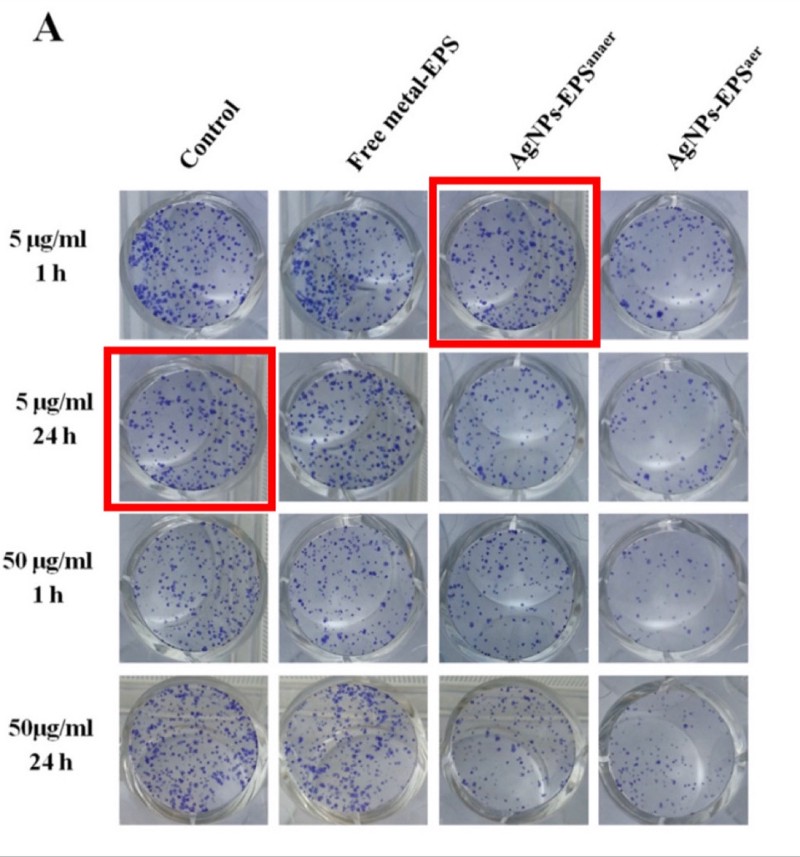
Photos of supposedly different samples in which two images are identical. From “Anticancer activity of biogenerated silver nanoparticles: an integrated proteomic investigation”. The journal investigated and concluded that this is fine.
It’s been known for years that a lot of claims made by scientists can’t be replicated. In some fields, the majority of all claims appear to not replicate due to a large mix of issues like overly lax thresholds for claiming statistical significance, poor study design and other somewhat subtle errors. But how much research is deliberate falsehood?
The sad truth is the size of the fraud problem is entirely unknown because the institutions of science have absolutely no mechanisms to detect bad behaviour whatsoever. Academia is dominated by (and largely originated) the same ideology calling for the total defunding of the police, so no surprise that they just assume everyone has absolute integrity all the time: research claims are constantly accepted at face value even when obviously nonsensical or fake. Deceptive research sails through peer review, gets published, cited and then incorporated into decision making. There are no rules and it’d be pointless to make any because there’s nobody to enforce them: universities are notorious for solidly defending fraudulent professors.
So let’s turn over the rock and see what crawls out. We’ll start with China and then turn our attention back to more western types of deception.
Chinese fraud studios
In 2018, the U.S. National Science Foundation announced that: “For the first time, China has overtaken the United States in terms of the total number of science publications.” Should the USA worry about this? Perhaps not. After some bloggers exposed an industrial research-faking operation that had generated at least 600 papers about experiments that never happened, a Chinese doctor reached out to beg for mercy:
Hello teacher, yesterday you disclosed that there were some doctors having fraudulent pictures in their papers. This has raised attention. As one of these doctors, I kindly ask you to please leave us alone as soon as possible… Without papers, you don’t get promotion; without a promotion, you can hardly feed your family… You expose us but there are thousands of other people doing the same. As long as the system remains the same and the rules of the game remain the same, similar acts of faking data are for sure to go on. This time you exposed us, probably costing us our job. For the sake of Chinese doctors as a whole, especially for us young doctors, please be considerate. We really have no choice, please!
Note the belief that “thousands of other people” are doing the same, and that these doctors need more than one paper to keep being promoted, so the 600 found so far is surely the tip of an iceberg given China’s size. There are about 3.8 million doctors in China implying that there are quite possibly tens of thousands, maybe hundreds of thousands of these things in circulation.
The fake papers are remarkable:
- They are so good they are undetectable in isolation. The NHS photo is an aberration – normally these papers get spotted by noticing re-used technical images across papers that claim to be different experiments by different people. The fake papers are probably produced by real scientists with access to real lab equipment. The use of spammy-looking Gmail accounts is also a signal because Gmail is banned in China (e.g.
BrendaWillingham12192@gmail.com,RosettajKirkland3814@gmail.com,CaseyPeiffer8311@gmail.com). The reliance on bot-generated Gmail accounts implies enormous scale. - They are peer reviewed and published in western journals. For instance, the Journal of Cellular Biochemistry by Wiley or Biomedicine & Pharmacotherapy by Elsevier. They claim to be doing advanced micro-biology on serious diseases: a typical title is something like “MicroRNA-125b promotes neurons cell apoptosis and Tau phosphorylation in Alzheimer’s disease”. Journals have no way to detect these papers and aren’t trying to develop any.
- Some of them present traditional Chinese medicine as scientific. TCM is more or less the Chinese equivalent of homeopathy with lots of herbal remedies, eating body parts of exotic animals to cure erectile dysfunction, and so on. But the Chinese Government is obsessed with it and thinks it’s the same as normal medicine. From the top down, Chinese scientists are expected to produce papers claiming that TCM works, and they do! Mostly this stuff stays in Chinese but the ever increasing reliance of western universities on Chinese funding means it’s now finding its way into the English language literature as well, e.g. “Probing the Qi of traditional Chinese herbal medicines by the biological synthesis of nano-Au” was published by the Royal Society of Chemistry.

Advert by a research faking operation. Credit to “Smut Clyde” and “TigerBB8”.
Most western scientists are too clever to buy a completely fake paper (or so we hope). But their promotion incentives are identical, and there are other techniques that let you publish as many fake papers as you want. Let’s turn our attention to…
Impossible numbers in western science
The case against science is straightforward: much of the scientific literature, perhaps half, may simply be untrue.
Richard Horton, editor of the Lancet
How many scientists just make up their data? A well known recent case of this was the Surgisphere scandal, in which a paper appeared in The Lancet that claimed to be based on a proprietary dataset of nearly 100,000 COVID-19 patients across over 670 U.S. hospitals. This figure was larger than the official case counts of some entire continents at the time, and there was no reason for hospitals to share tightly controlled medical data with a random company nobody had heard of, so the claim was implausible on its face. Sure enough, when challenged it turned out none of the authors had ever actually seen the data, just summaries of it provided by one guy, who on investigation had a long track record of dishonesty. The Lancet probably accepted this paper because it made Trump look bad and the editor (Horton, quoted above) appears to hate Trump more than he hates bad science.
There are some other cases like this that came to light over the years, like the story of Brian Wansink, or that of Paolo Macchiarini, who left a trail of dead patients in his wake. But while anecdotes about individual cases are interesting, can we be more rigorous?
One clue comes from automated tools that scan research papers looking for mathematically impossible numbers, which can sometimes be detected even in the absence of the raw original data. In recent years a few such tools have been developed and deployed, mostly against psychology and food science.
- The statcheck program showed that “half of all published psychology papers… contained at least one p-value that was inconsistent with its test”.
- The GRIM program showed that of the papers it could verify, around half contained averages that weren’t possible given the sample sizes, and more than 20% contained multiple such inconsistencies.
- The SPRITE program detected various experiments on food that would have required subjects to eat implausible quantities (e.g. a child needing to eat 60 carrots in a single sitting, or 3/4 kilogram of crisps).
Being flagged by a stats checker doesn’t guarantee the data is made up: GRIM can detect simple mistakes like typos and SPRITE requires common sense to detect that something is wrong (i.e., no child will eat a plate of 60 carrots). But when there are multiple such problems in a single paper, things start to look more suspicious. The fact that half of all papers had incorrect data in them is concerning, especially because it seems to match Richard Horton’s intuitive guess at how much science is simply untrue. And the GRIM paper revealed a deeper problem: more than half of the scientists refused to provide the raw data for further checking, even though they had agreed to share it as a condition of being published. This is rather suspicious.
One of the difficulties with detecting scientific fraud is that the line between dishonesty and simple absurdity can get quite blurry. Sometimes scientists “calculate” data that is clearly wrong, but don’t actually try to hide or it may even admit to it in the paper, knowing full well that nobody cares and nonsensical data won’t actually matter. Here’s an example from a COVID modelling paper:
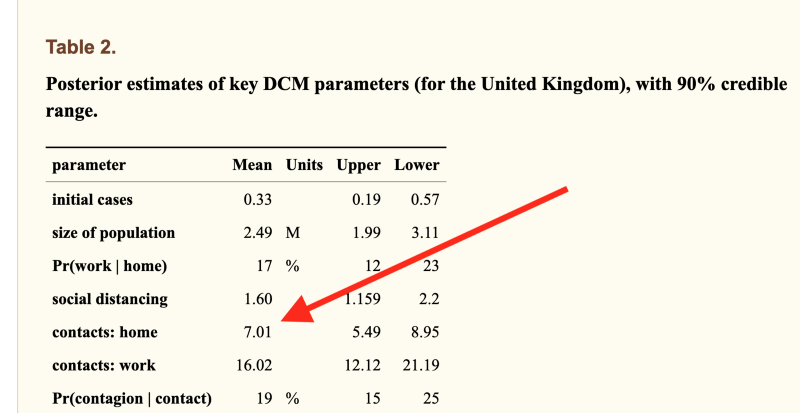
The model was allowed to calculate that the average Brit must live with 7 other people, because it couldn’t obtain data fit otherwise (actual number=2.4). This one comes from University College London, is written by 12 neuroscientists, passed peer review and has 37 citations. The peer reviewer noticed that the incorrect number was in the paper but signed off on it anyway.
For decades psychiatrists published research into the “gene for depression” 5-HTTLPR. They created an entire literature not only linking the gene to depression but explaining how it worked, linking it to parenting styles, developing treatments based up on it. Over 450 papers were published on the topic. Eventually a geneticist discovered what they were doing and used DNA databanks to point out that none of those papers could possibly be true.
Sometimes numbers aren’t “wrong” but are instead logically vacuous. The Flaxman et al paper from Imperial College that tried to prove lockdowns work had the usual problem of statistically implausible numbers, but more importantly was built on circular logic: their model assumed only government interventions could end epidemics. This is obviously nonsense and they breezily admitted it in the paper, where they said their work was “illustrative only” and that “in reality even in the absence of government interventions we would expect Rt to decrease”. No problem: this fictional illustration got published in Nature and the authors presented the model’s outputs as scientific proof of their own assumption to the media. The paper is vacuous mathematical obfuscation, but scientists either can’t tell or don’t care: it has racked up over 1,300 citations and the number is still growing rapidly. To put that number in perspective, in physics the top 1% of all researchers have around 2,000 citations over their entire career.
Time to assume that health research is fraudulent until proven otherwise?
Earlier this month, the BMJ published an astounding blog post with the same title as this section. There’s no need to add anything because simply quoting it is sufficient:
The anaesthetist John Carlisle analysed 526 trials submitted to Anaesthesia and found that… when he was able to examine individual patient data in 153 studies, 67 (44%) had untrustworthy data and 40 (26%) were zombie trials… [Ben] Mol’s best guess is that about 20% of trials are false. Very few of these papers are retracted.
We have now reached a point where those doing systematic reviews must start by assuming that a study is fraudulent until they can have some evidence to the contrary.
Richard Smith
Richard Smith is a former editor of the BMJ, cofounder of the Committee on Medical Ethics (COPE), for many years the chair of the Cochrane Library Oversight Committee, and a member of the board of the U.K. Research Integrity Office.
Or put another way, an overseer of the Research Integrity Office believes research has no integrity.
What can be done?
600 fraudulent papers here, 450 over there, 1300+ citations of just one bad paper… pretty quickly it starts adding up.
We’re often told science is self-correcting. Is that true? Probably not. “The Science Reform Brain Drain” is perhaps the bleakest essay I’ve read this year. Reformers like the men who developed SPRITE and GRIM have been giving up and leaving science entirely. Pointing out in public that your colleagues are dishonest is never a great career move, and the work was often futile. One scientist who quit and went into industry summed up his fraud detection work like this:
The clearest consequence of my actions has been that Zhang has gotten better at publishing. Every time I reported an irregularity with his data, his next article would not feature that irregularity.
Even when a bull enters the China shop and gets a few papers retracted, it doesn’t actually matter because it has little effect: retracted papers keep getting cited for years afterwards and actually may be cited more than non-retracted papers, because one of the effects of retraction is that the article becomes free to download.
In the past year most talk of bad science has been about models with bad assumptions. This is an issue but has been hiding problems that are far worse: scientists are buying fake papers, Photoshopping evidence, refusing to upload their data, knowingly publishing numbers that cannot be correct, citing papers that were retracted for being fraudulent and (of course) presenting mathematical obfuscations of what they want to be true as if it were science. Journals usually ignore fraud reports entirely, or when put under pressure let scientists submit “corrected” versions of their papers. And worst of all, the journal editors that are responsible for scientific gatekeeping know all this is happening, but aren’t doing anything about it.
In fact, very little can be done because above all, universities rely on reputation and don’t want anyone to find out about bad behaviour, so they fight tooth and nail to protect academics no matter how badly they are behaving. There are no rules. Any rules that are alleged to exist turn out when tested to be illusions.
Claims made by scientists are automatically trusted by the majority of people. Maybe they shouldn’t be?
Mike Hearn is a former Google software engineer. You can read his blog at Plan 99.
No comments yet.
Featured Video

BIRX POINTS THE FINGER AT FAUCI, DENIES LOCKDOWN BLAME
or go to
Aletho News Archives – Video-Images
Book Review
Lobbying for Zionism reviewed by David Miller
By David Miller | July 30, 2026
Did Zionism begin as a Christian project which was only later a Jewish movement?
This is what Ilan Pappé says in the book Lobbying for Zionism.
In my review of the book, I show this is wrong.
Here is an excerpt… continue
Blog Roll
 Aletho News
Aletho News- Singapore police open probe over Palestinian flag displayed at Massive Attack concert
- Saudi Arabia’s militarization of Red Sea will not safeguard shipping in waterway: Yemen
- Yemen vs. Saudi Arabia: A Strategy of Strangulation and Asymmetric Response
- Germany scrambles to evade Nicaragua’s landmark Gaza genocide case at ICJ
- Iceland’s forthcoming referendum on EU membership
- Ukraine committing ‘piracy’ – Rosatom CEO
- Lobbying for Zionism reviewed by David Miller
- Navy retiring USS Fort Worth halfway through lifespan
- BIRX POINTS THE FINGER AT FAUCI, DENIES LOCKDOWN BLAME
- Russian Strike on US Drone Factory in Kiev Makes Clear – NATO’s Overseas MIC Footprint Is Fair Game
- If Americans Knew
- As Gazans suffer, Israel says No to ceasefire package – Daily Update
- The Satanic Hazing Rituals of the IDF
- Israel Is Paying Millions to Train AI Chatbots How to Talk About Gaza. It’s Working.
- Right now, it’s all about what “Netanyahu wants” – Daily Update
- The Killing of Awdah Hathaleen: Beyond a Settler Crime
- Republican Voters are Turning against the Iran War
- Haley Stevens Is an Enemy of International Law
- Were the first Zionists Christian? A review.
- Ben Gvir’s crocodiles are the latest weapon in Israel’s animal warfare on Palestinians
- CIA Assessment Details Israel’s Race to Make the U.S.-Israel Alliance Irreversible
- No Tricks Zone
- New Research Finds Increasing CO2 Induces Cooling In The Lower Atmosphere Over The Arctic
- Germany’s Industrial Suicide… Grid Agency Prepares Secret Power Rationing Plans Amid Electric Power Bottlenecks
- ECMWF Models Throwing Cold Water On Extreme Germany Heat Wave Forecast Next Week
- Greenland’s Ice Sheet Was Supposed To Be Rapidly Melting Away. It Hasn’t Been.
- Global Temperature Trend Has Cooled Over The Past 6500 Years, Scientists Have Found
- Wind Energy Means Going Back To The Middle Ages, Says German Professor Horst-Joachim Lüdecke
- New Study: A 40-Fold Increase In Earth’s Main Greenhouse Gas Contributes To Cooling The Ocean
- New Study Highlights The ‘Dominant Role’ Of Aerosol/Cloud Interactions In Shaping Climate
- Munich’s First-Ever Green Party Mayor Declares First Ever City Water Use Restrictions… Fines Up to 50,000 €!
- Experimental Lab Research: The Climate Sensitivity To A 400-Fold Increase In CO2 Is 0.1°C

Leave a comment